

As page tables are per-process data structures, a pointer to the page table is stored with the other register values (like the instruction pointer) in the process control block of each process. When the CPU scheduler selects a process for execution, it must reload the user registers and the appropriate hardware page-table values from the stored user page table.
The hardware implementation of the page table can be done in several ways. In the simplest case, the page table is implemented as a set of dedicated high-speed hardware registers, which makes the page-address translation very efficient. However, this approach increases context-switch time, as each one of these registers must be exchanged during a context switch.
The use of registers for the page table is satisfactory if the page table is reasonably small (for example, 256 entries). Most contemporary CPUs, however, support much larger page tables (for example, 220 entries). For these machines, the use of fast registers to implement the page table is not feasible. Rather, the page table is kept in main memory, and a page-table base register (PTBR) points to the page table. Changing page tables requires changing only this one register, substantially reducing context-switch time.
Translation Look-Aside Buffer
Although storing the page table in main memory can yield faster context switches, it may also result in slower memory access times. Suppose we want to access location i. We must first index into the page table, using the value in the PTBR offset by the page number for i. This task requires one memory access. It provides us with the frame number, which is combined with the page offset to produce the actual address. We can then access the desired place in memory. With this scheme, two memory accesses are needed to access data (one for the page-table entry and one for the actual data). Thus, memory access is slowed by a factor of 2, a delay that is considered intolerable under most circumstances.
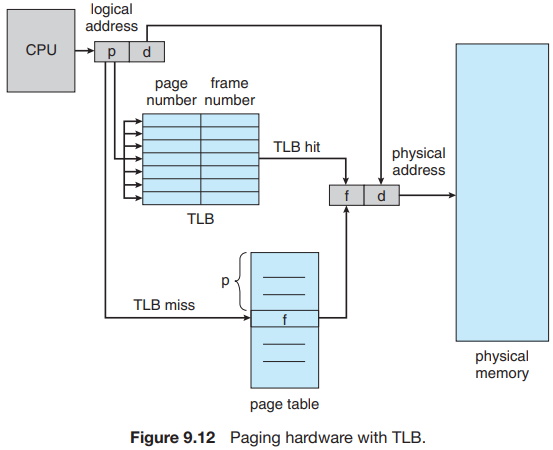
The standard solution to this problem is to use a special, small, fast-lookup hardware cache called a translation look-aside buffer (TLB). The TLB is associative, high-speed memory. Each entry in the TLB consists of two parts: a key (or tag) and a value. When the associative memory is presented with an item, the item is compared with all keys simultaneously. If the item is found, the corresponding value field is returned. The search is fast; a TLB lookup in modern hardware is part of the instruction pipeline, essentially adding no performance penalty. To be able to execute the search within a pipeline step, however, the TLB must be kept small. It is typically between 32 and 1,024 entries in size. Some CPUs implement separate instruction and data address TLBs. That can double the number of TLB entries available, because those lookups occur in different pipeline steps. We can see in this development an example of the evolution of CPU technology: systems have evolved from having no TLBs to having multiple levels of TLBs, just as they have multiple levels of caches.
The TLB is used with page tables in the following way. The TLB contains only a few of the page-table entries. When a logical address is generated by the CPU, the MMU first checks if its page number is present in the TLB. If the page number is found, its frame number is immediately available and is used to access memory. As just mentioned, these steps are executed as part of the instruction pipeline within the CPU, adding no performance penalty compared with a system that does not implement paging.
If the page number is not in the TLB (known as a TLB miss), address translation proceeds, where a memory reference to the page table must be made. When the frame number is obtained, we can use it to access memory (Figure 9.12). In addition, we add the page number and frame number to the TLB, so that they will be found quickly on the next reference.
If the TLB is already full of entries, an existing entry must be selected for replacement. Replacement policies range from least recently used (LRU) through round-robin to random. Some CPUs allow the operating system to participate in LRU entry replacement, while others handle the matter themselves. Furthermore, some TLBs allow certain entries to be wired down, meaning that they cannot be removed from the TLB. Typically, TLB entries for key kernel code are wired down.
Some TLBs store address-space identifier (ASIDs) in each TLB entry. An ASID uniquely identifies each process and is used to provide address-space protection for that process. When the TLB attempts to resolve virtual page numbers, it ensures that the ASID for the currently running process matches the ASID associated with the virtual page. If the ASIDs do not match, the attempt is treated as a TLB miss. In addition to providing address-space protection, an ASID allows the TLB to contain entries for several different processes simultaneously. If the TLB does not support separate ASIDs, then every time a new page table is selected (for instance, with each context switch), the TLB must be flushe (or erased) to ensure that the next executing process does not use the wrong translation information. Otherwise, the TLB could include old entries that contain valid virtual addresses but have incorrect or invalid physical addresses left over from the previous process.
The percentage of times that the page number of interest is found in the TLB is called the hit ratio. An 80-percent hit ratio, for example, means that we find the desired page number in the TLB 80 percent of the time. If it takes 10 nanoseconds to access memory, then a mapped-memory access takes 10 nanoseconds when the page number is in the TLB. If we fail to find the page number in the TLB then we must first access memory for the page table and frame number (10 nanoseconds) and then access the desired byte in memory (10 nanoseconds), for a total of 20 nanoseconds. (We are assuming that a page table lookup takes only one memory access, but it can take more, as we shall see.) To find the effective memory-access time, we weight the case by its probability:
effective access time = 0.80 x 10 + 0.20 x 20 = 12 nanoseconds
In this example, we suffer a 20-percent slowdown in average memory-access time (from 10 to 12 nanoseconds). For a 99-percent hit ratio, which is much more realistic, we have
effective access time = 0.99 x 10 + 0.01 x 20 = 10.1 nanoseconds
This increased hit rate produces only a 1 percent slowdown in access time.
As noted earlier, CPUs today may provide multiple levels of TLBs. Calculating memory access times in modern CPUs is therefore much more complicated than shown in the example above. For instance, the Intel Core i7 CPU has a 128-entry L1 instruction TLB and a 64-entry L1 data TLB. In the case of a miss at L1, it takes the CPU six cycles to check for the entry in the L2 512-entry TLB. A miss in L2 means that the CPU must either walk through the page-table entries in memory to find the associated frame address, which can take hundreds of cycles, or interrupt to the operating system to have it do the work.
A complete performance analysis of paging overhead in such a system would require miss-rate information about each TLB tier. We can see from the general information above, however, that hardware features can have a significant effect on memory performance and that operating-system improvements (such as paging) can result in and, in turn, be affected by hardware changes (such as TLBs).
TLBs are a hardware feature and therefore would seem to be of little concern to operating systems and their designers. But the designer needs to understand the function and features of TLBs, which vary by hardware platform. For optimal operation, an operating-system design for a given platform must implement paging according to the platform's TLB design. Likewise, a change in the TLB design (for example, between different generations of Intel CPUs) may necessitate a change in the paging implementation of the operating systems that use it.
About the Authors
Abraham Silberschatz is the Sidney J. Weinberg Professor of Computer Science at Yale University. Prior to joining Yale, he was the Vice President of the Information Sciences Research Center at Bell Laboratories. Prior to that, he held a chaired professorship in the Department of Computer Sciences at the University of Texas at Austin.
Professor Silberschatz is a Fellow of the Association of Computing Machinery (ACM), a Fellow of Institute of Electrical and Electronic Engineers (IEEE), a Fellow of the American Association for the Advancement of Science (AAAS), and a member of the Connecticut Academy of Science and Engineering.
Greg Gagne is chair of the Computer Science department at Westminster College in Salt Lake City where he has been teaching since 1990. In addition to teaching operating systems, he also teaches computer networks, parallel programming, and software engineering.

The tenth edition of
Operating System Concepts
has been revised to keep it fresh and up-to-date with contemporary examples of how operating
systems function, as well as enhanced interactive elements to improve learning and the student's
experience with the material. It combines instruction on concepts with real-world applications
so that students can understand the practical usage of the content. End-of-chapter problems,
exercises, review questions, and programming exercises help to further reinforce important
concepts. New interactive self-assessment problems are provided throughout the text to help
students monitor their level of understanding and progress. A Linux virtual machine (including
C and Java source code and development tools) allows students to complete programming exercises
that help them engage further with the material.
A reader in the U.S. says, "This is what computer-related books should be like. It is thorough, in depth, information packed, authoritative, and exhaustive. You cannot get this kind of excellent information from the Internet - or many other computer books these days. It's a shame that quality computer books are declining so rapidly in number. I hope they continue to update and publish this book for many years to come.

More Computer Architecture Articles:
• Monolithic Kernel vs Microkernel vs Hybrid Kernel
• Windows Operating System Services, Functions, Routines, Processes, Threads, and Jobs
• AMD's Microarchitectures
• Multi-Processor Scheduling
• Electronic Circuits
• The Use of SOI (Silicone on Insulator) Wafers in MEMS (Micro-Electro-Mechanical Systems) Production
• Basic Arithmetic Logic Unit (ALU) Circuitry
• ARM Cortex-A72 Registers
• Digital Logic Levels and Transfer Characteristics
• AMD's Phenom Processor